Post Mortem: How did the AWS Outage Impact Blockchain Network Operations?
On Monday, October 20, 2025, Amazon Web Services (AWS) experienced a partial service disruption that rippled across the Internet, temporarily degrading performance for infrastructure providers and blockchain networks.
The outage, which lasted from approximately 06:48 UTC to 09:40 UTC on October 20th, originated from a DNS issue affecting the DynamoDB service, which underpins core components of many enterprise applications and websites.
While the outage primarily affected services and businesses using traditional web-based technologies (’Web2’), we also observed disruption to blockchain infrastructure, primarily the Base L2 network.
What Actually Happened
According to AWS’s internal reports and confirmed by multiple third-party monitors, a misconfigured DNS subsystem in the DynamoDB control plane caused lookup failures across the AWS us-east-1 region.
These failures intermittently prevented clients from resolving table endpoints, which in turn stalled applications built on top of DynamoDB or services that depend on it for caching, indexing, or coordination. The incident persisted for roughly 100 minutes, after which DNS resolution was restored and full DynamoDB functionality resumed.
Despite most applications and websites recovering swiftly following the primary outage, many others experienced delays in achieving a full recovery as a long queue of requests was processed and resolved throughout October 20th.
Impact on Blockchain Networks
While the incident was global in scope, the most visible blockchain impact occurred on Base, an Ethereum Layer-2 network built on the OP Stack.
At approximately 08:23 UTC, the Base status page reported “limited network capacity,” identifying AWS as the underlying cause. By 08:39 UTC, Base confirmed that a major AWS outage was affecting its infrastructure, leading to a reduction in available sequencer and RPC capacity.
Transaction inclusion times increased as the incident unfolded, with many users experiencing delays before transactions appeared in blocks. By 09:50 UTC, as AWS restored service, Base reported that transaction capacity and batch submission had returned to normal.
Additional reporting surfaced varying levels of disruption for other networks, including partial infrastructure outages for Polygon and node issues for Solana.
The On-Chain Evidence
Metrika recorded significant deviations across several Key Risk Indicators (KRIs) related to Base network health, which bear the signature of the AWS outage and its impact:
- Block space utilization dropped to ~16%, less than half of typical levels, as user transactions faced delays to be successfully included in blocks.
- Average block finalization time spiked by more than 5x typical levels (~14 mins) to an average of 78 mins in the hour during the core AWS outage.
- Transactions per second (TPS) processed by the network saw a sustained dip of nearly 40% from a stable 120 tx/s either side of the outage window.
The Base network operates using a centralized sequencer design, whereby a sequencer(s) processes transactions and posts data to the underlying L1 (Ethereum).
The observed response of our KRI metrics suggests that the Coinbase Sequencer, which processes transactions on Base, may have been significantly impacted by the AWS outage and ultimately contributed to the transaction delays experienced by network users.
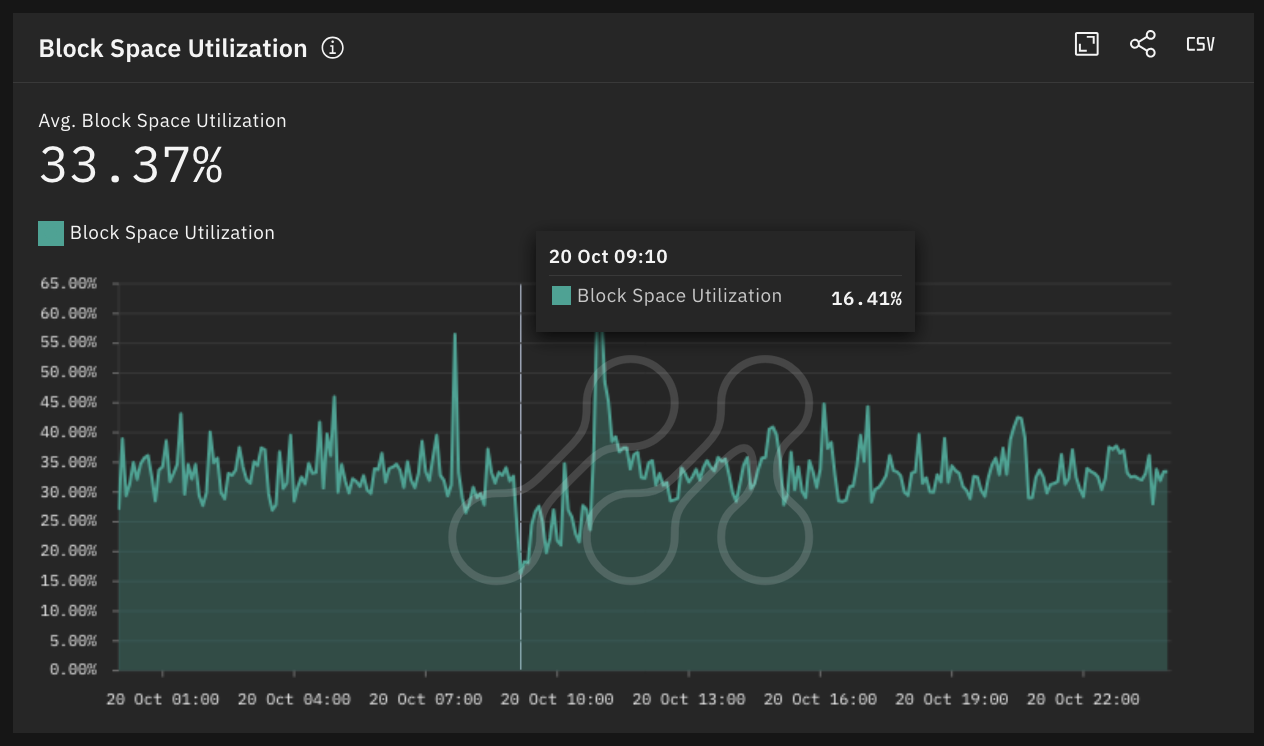
Average Block Space Utilization on Base Source: Metrika Platform (Time Zone UTC +1)
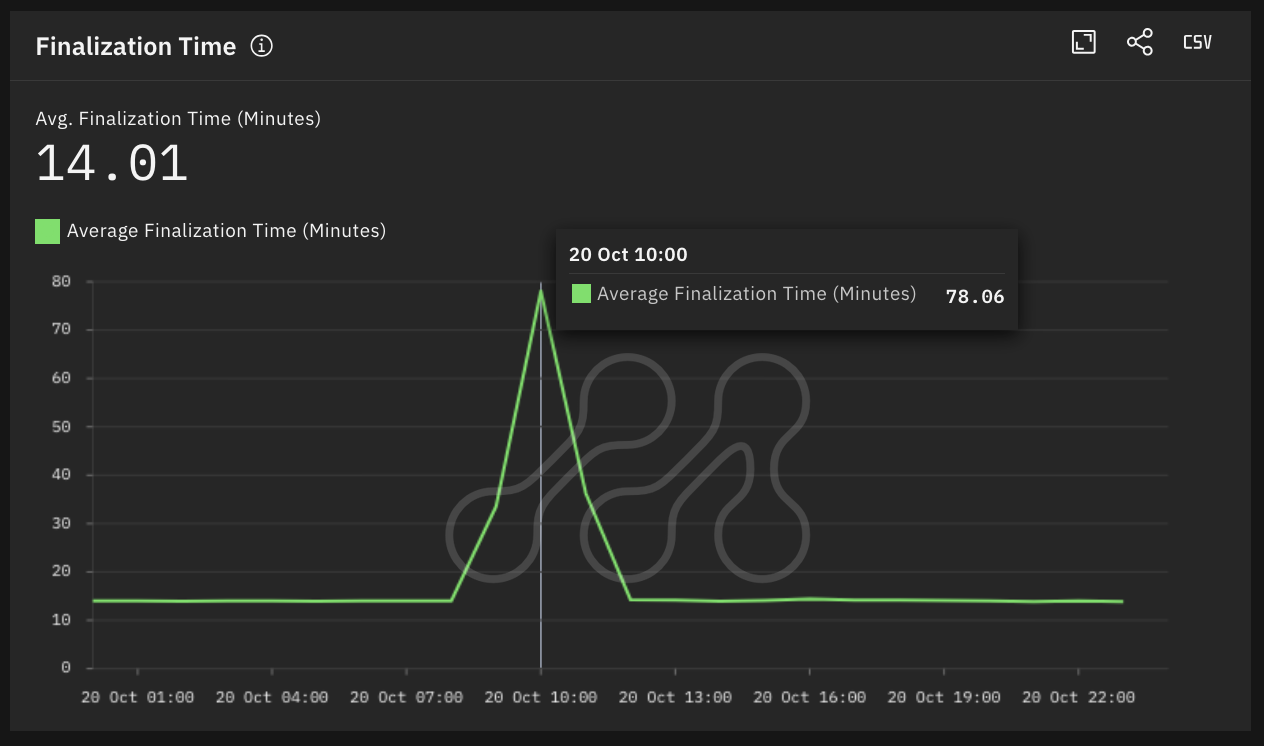
Average Block Finalization Time on Base Source: Metrika Platform (Time Zone UTC +1)

Average Transactions per Second (TPS) on Base Source: Metrika Platform (Time Zone UTC +1)
Risk Monitoring Lessons for Institutions
The October 20th AWS incident underlines the significant single point of failure (SPOF) risk inherent to L2 blockchains and scaling solutions, such as the Base network, that rely on a centralized entity model.
Although many such networks are committed to decreasing their exposure to SPOF risk over time, their reliance on the operations and practices on a single entity in the interim phase can make them more vulnerable to performance issues.
In the case of Ethereum, there is a wider distribution of cloud providers used by network nodes, with just 14% hosted by Amazon. This makes the network comparatively less exposed to performance issues from outages similar to the October 20th incident.
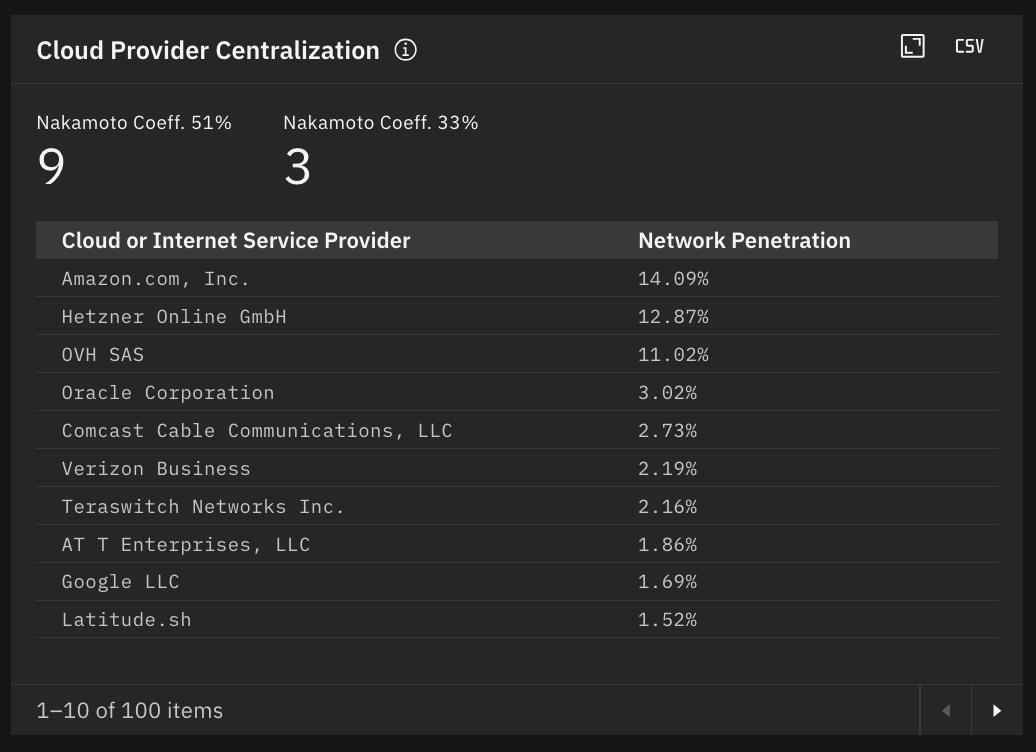
Cloud Provider Distribution and Nakamoto Coefficients (51%, 33%) on the Ethereum Network Source: Metrika Platform
The impacts of the AWS outage on the wider digital assets ecosystem were not limited to blockchain networks themselves, with several exchanges and service providers severely affected by the event.
The AWS incident highlights that the scope of digital asset risk extends beyond the core infrastructure of blockchain networks, including consensus mechanisms and smart contracts, to the existing Web2 technology stack upon which they rely.
Many blockchain networks and most of their user interfaces, such as exchanges and wallets, are built on top of the existing layers and architecture of the modern Internet. The AWS incident serves as evidence that these factors must be considered when assessing and monitoring the risks associated with digital assets.
A failure in one foundational service can propagate to both the blockchain networks themselves and the web-based interfaces that users rely upon, which must be taken into consideration for digital asset risk analysts in the future.
Photo by İsmail Enes Ayhan on Unsplash