Post Mortem: What Happened on Base on August 5, 2025
On August 5, 2025, the Base network experienced a sequencer incident that temporarily halted normal transaction processing for approximately 33 minutes. The incident occurred at 06:07 UTC when block production abruptly stopped at block height 33,792,704, lasting until approximately 6:40 UTC. While the Base team’s status page indicated “halted block production,” the reality was more nuanced, and this distinction matters for monitoring and risk assessment.
What Actually Happened
Despite the official language used on Base’s status page, blocks continued to be produced as normal, and the chain kept growing. The Metrika Platform uptime chart correctly showed 100% uptime throughout the incident, reflecting this technical reality.
The key caveat: these blocks were effectively empty of user transactions, containing only system transactions (typically just one per block). You can validate this against any Base explorer, such as Basescan, which shows the first near-empty block produced at the network’s regular ~2-second interval.
The Technical Details
This behavior represents a failsafe mechanism built into the OP stack that activates when the sequencer loses its anchor to Ethereum. According to the official post-mortem published by the Base team, the outage was caused by a fault in Conductor, the internal cluster manager responsible for orchestrating sequencer node transitions during failovers.
The outage began at 06:07 UTC on Aug. 5, when the active sequencer fell behind due to congestion from on-chain activity. While Base’s Conductor module — a core component of the OP Stack designed to maintain uptime — correctly attempted to shift leadership to a standby sequencer, the new instance had not been fully provisioned and was unable to produce blocks.
This is referred to as an “unsafe-head delay,” a technical fault that occurs when the new sequencer lacks access to fresh Ethereum L1 blocks (its “L1 origin”) and refuses to process normal user transactions as a safety measure.
This likely continued while the new sequencer was bootstrapping (no mempool, no healthy L1 feed yet) and eventually recovered, with the team emphasizing that no chain reorganization occurred and user funds remained secure throughout the incident.
How Metrika Detected the Real Impact
While our uptime monitoring showed the chain remained operational, Metrika captured the incident through at least three other Key Risk Indicators (KRIs):
- Transactions Per Second (TPS): collapsed to near zero
- Transactions Per Block: dropped to system transactions only
- Block Space Utilization: fell to minimal levels
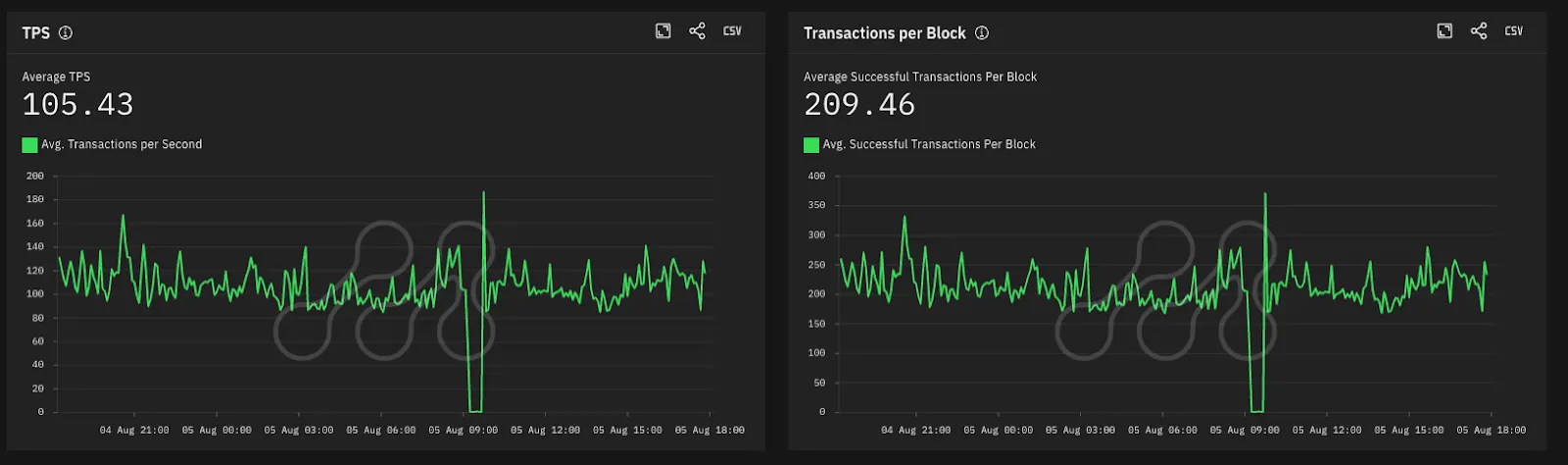
Source: Metrika Platform (Time Zone UTC +3)
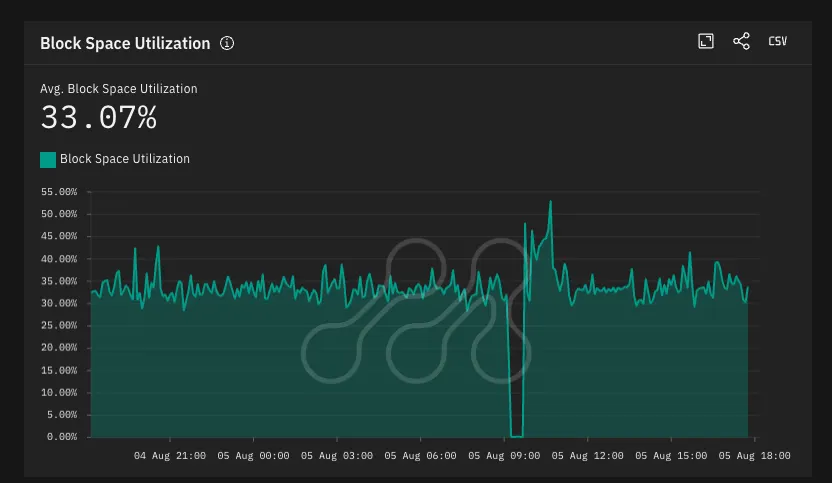
Source: Metrika Platform (Time Zone UTC +3)
All three metrics remained depressed for the ~33-minute duration until the new sequencer was fully operational.
The Risk Monitoring Lesson
This incident highlights why comprehensive risk monitoring matters. A “Live Risk Assessment” of Base that includes these KRIs would have provided immediate alerts through your preferred channels (email, Slack, etc.) because all three metrics would have exceeded their threshold configurations, as you see in the example below.
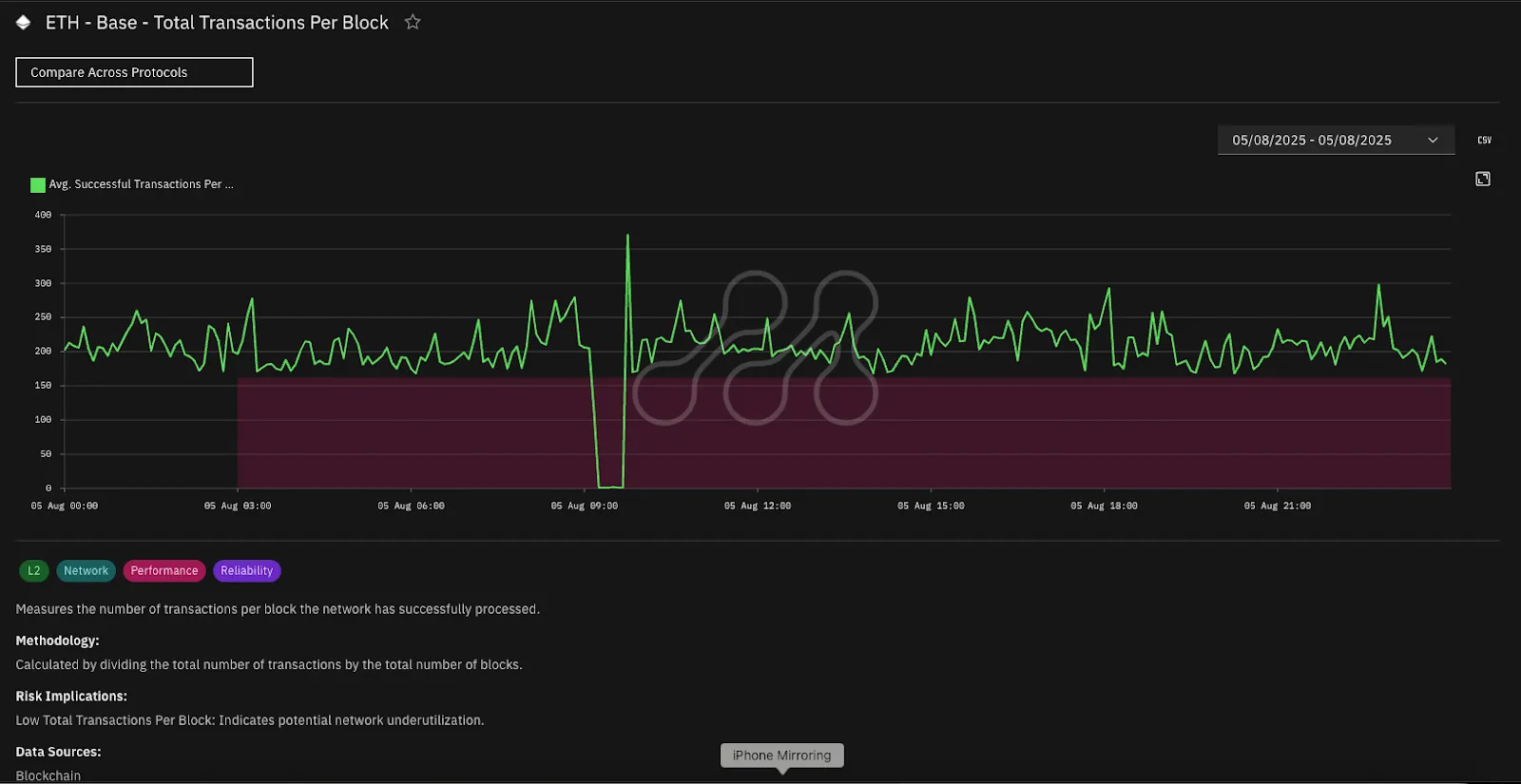
Source: Metrika Platform (Time Zone UTC +3)
Rather than relying solely on binary uptime metrics or official status pages, monitoring the actual network activity provides a clearer picture of user-facing impact, which is what ultimately matters for applications and users dependent on the network.
Sources and Additional Context
This incident marks the second major outage for Base since its public launch, following a similar 43-minute disruption in September 2023. The network has experienced rapid growth recently, with daily token launches surging from 6,649 on July 1 to approximately 50,000 by month-end, which may have contributed to the traffic spike that triggered the incident.
Key Sources:
- Base Official Status Page: status.base.org
- CoinDesk: “Base Says Sequencer Failure Caused Block Production Halt of 33 Minutes”
The incident has renewed concerns about centralized sequencer models and highlighted the importance of comprehensive monitoring that goes beyond simple uptime checks to capture real user impact.